信用评分模型的评估指标
最近在做某银行的客户信用评分模型时接触到几个模型稳定性的评估指标,只要有PSI、VOI、K-S值等统计学概念,之前不太了解,这里记录一下。
预测能力指标
用于评估模型对违约事件的预测能力,比如:
- WOE/VOI
- ROC/AUC
- K-S指标
- GINI系数
WOE&VOI
WOE(Weight of Evidence)叫做证据权重,VOI(Value of Information )叫做信息价值,是一组评估变量的预测能力的指标。也就是说,当我们想要拿出证据证明“年龄”这个变量对于违约概率是否有影响的时候,可以使用这个指标评估年龄到底对违约概率的影响有多大。
$$
WOE = ln[(正常/总正常)/(违约/总违约)]
$$
$$
VOI =
$$
ROC/AUC
这个就不再详写了,学过机器学习的都知道。
K-S(Kolmogorov-Smirnov)
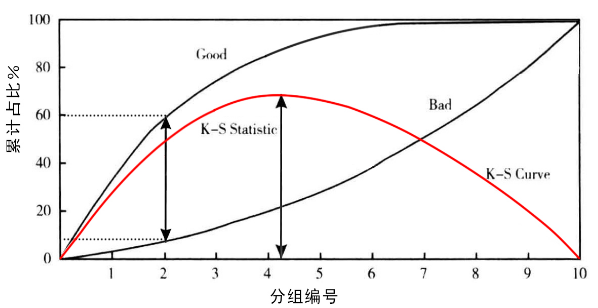
作为一个模型,我们当然希望这个模型能够帮我们挑选到最多的好客户,同时不要放进来那么多坏客户。K-S值就是一个这样思路的指标。比如,在完成一个模型后,将测试模型的样本平均分成10组,以好样本占比降序从左到右进行排列,其中第一组的好样本占比最大,坏样本占比最小。这些组别的好坏样本占比进行累加后得到每一组对应的累计的占比。好坏样本的累计占比随着样本的累计而变化(图中Good/Bad两条曲线),而两者差异最大时就是我们要求的K-S值(图中比较长的直线箭头的那个位置)。
KS值的取值范围是[0,1]。通常来说,值越大,表明正负样本区分的程度越好。一般,KS值>0.2就可认为模型有比较好的预测准确性。
GINI系数
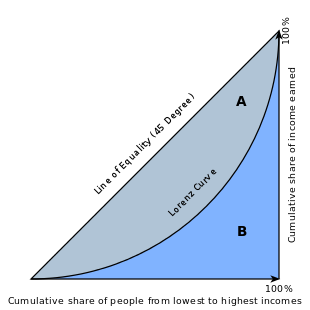
还记得经济学中那个著名的基尼系数吗?下图应该可以让你回忆起来。将一个国家所有的人口按最贫穷到最富有进行排列,随着人数的累计,这些人口所拥有的财富的比例也逐渐增加到100%,按这个方法得到图中的曲线,称为洛伦兹曲线。基尼系数就是图中A/B的比例。可以看到,假如这个国家最富有的那群人占据了越多的财富,贫富差距越大,那么洛伦茨曲线就会越弯曲,基尼系数就越大。
同样的,假设我们把100个人的信用评分按照从高到低进行排序,以横轴为累计人数比例,纵轴作为累计坏样本比例,随着累计人数比例的上升,累计坏样本的比例也在上升。如果这个评分的区分能力比较好,那么越大比例的坏样本会集中在越低的分数区间,整个图像形成一个凹下去的形状。所以洛伦兹曲线的弧度越大,基尼系数越大,这个模型区分好坏样本的能力就越强。
稳定性指标
用于评估模型在训练样本和测试样本中预测能力的一致性,如PSI指标。
PSI(Population Stability Index)
PSI(Population Stability Index)叫做群体稳定性指标,用于衡量两组样本的评分是否有显著差异。PSI = sum((实际占比-预期占比)*ln(实际占比/预期占比)
举个栗子,假设在训练一个评分模型时,我们将样本评分按从小到大排序分成10组,那么每组会有不同的样本数量占比P1;评分模型制作出来之后,我们试用这个模型去预测新的一组数据样本,按上面的方法同样按评分分成10组,每组也会有一定的样本数量占比P2。PSI可以帮助我们量化P1和P2,即预期占比与实际占比的差距。
References: